Pairs Trading Strategies in Python

Pairs Trading Strategies Using Python
When it comes to making money in the stock market, there are a myriad of different ways to make money. And it seems that in the finance community, everywhere you go, people are telling you that you should learn Python. After all, Python is a popular programming language which can be used in all types of fields, including data science. There are a large number of packages that can help you meet your goals, and many companies use Python for development of data-centric applications and scientific computation, which is associated with the financial world.
Most of all Python can help us utilize many different trading strategies that (without it) would by very difficult to analyze by hand or with spreadsheets. One of the trading strategies we will talk about is referred to as Pairs Trading.
Pairs Trading
Pairs trading is a form of mean-reversion that has a distinct advantage of always being hedged against market movements. It is generally a high alpha strategy when backed up by some rigorous statistics. The stratey is based on mathematical analysis.
The prinicple is as follows. Let’s say you have a pair of securities X and Y that have some underlying economic link. An example might be two companies that manufacture the same product, or two companies in one supply chain. If we can model this economic link with a mathematical model, we can make trades on it.
In order to understand pairs trading, we need to understand three mathematical concepts: Stationarity, Integration, and Cointegration.
Note: This will assume everyone knows the basics of hypothesis testing.
import numpy as np
import pandas as pd
import statsmodels
import statsmodels.api as sm
from statsmodels.tsa.stattools import coint, adfuller
import matplotlib.pyplot as plt
import seaborn as sns; sns.set(style="whitegrid")
Stationarity/Non-Stationarity
Stationarity is the most commonly untested assumption in time series analysis. We generally assume that data is stationary when the parameters of the data generating process do not change over time. Else consider two series: A and B. Series A will generate a stationary time series with fixed parameters, while B will change over time.
We will create a function that creates a z-score for probability density function. The probability density for a Gaussian distribution is:
$$ p(x) = \frac{1}{\sqrt{2\pi\sigma^{2}}}e^{-\frac{(x-\mu)^{2}}{2\sigma^{2}}}$$
where $\mu$ is the mean and $\sigma$ the standard deviation. The square of the standard deviation, $\sigma^{2}$, is the variance. The empircal rule dictates that 66% of the data should be somewhere between $x+\sigma$ and $x-\sigma$, which implies that the function numpy.random.normal is more likely to return samples lying close to the mean, rather than those far away.
def generate_data(params):
mu = params[0]
sigma = params[1]
return np.random.normal(mu, sigma)
From there, we can create two plots that exhibit a stationary and non-stationary time series. The left time series will be stationary, whereas the right will be non-stationary.
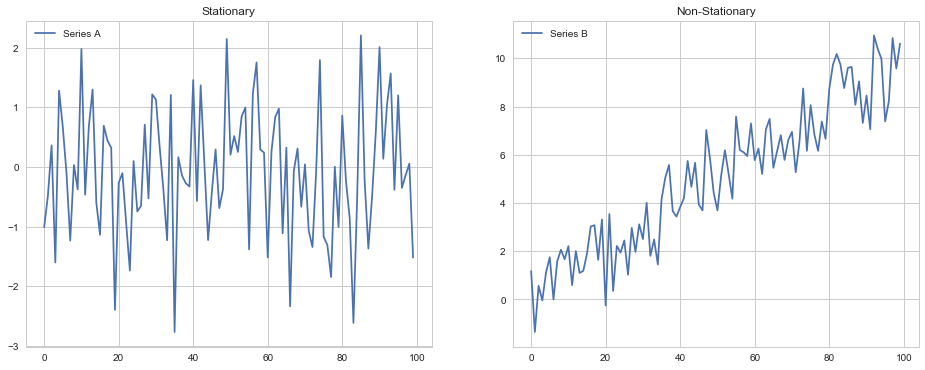
Why Stationarity is Important
Many statistical tests require that the data being tested are stationary. Using certain statistics on a non-stationary data set may lead to garbage results. As an example, let’s take an average through our non-stationary $B$.
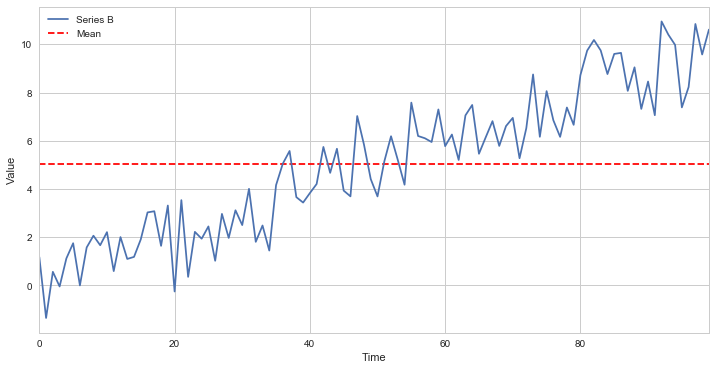
The computed mean will show that the mean of all data points, but won’t be useful for any forecasting of the future state. It’s meaningless when compared with any specific time, as it’s a collection of different states at different times mashed together. This is just a simple and clear example of why non-stationarity can distort the analysis, much more subtle problems can arise in practice.
Augmented Dickey Fuller
In order to test for stationarity, we need to test for something called a unit root. Autoregressive unit root test is based on the following hypothesis test:
$$ \begin{aligned} H_{0} & : \phi =\ 1\ \implies y_{t} \sim I(0) \ | \ (unit \ root) \ H_{1} & : |\phi| <\ 1\ \implies y_{t} \sim I(0) \ | \ (stationary) \ \end{aligned} $$
It’s referred to as a unit root tet because under the null hypothesis, the autoregressive polynominal of $\mathcal{z}_{t},\ \phi (\mathcal{z})=\ (1-\phi \mathcal{z}) \ = 0$, has a root equal to unity.
$y_{t}$ is trend stationary under the null hypothesis. If $y_{t}$is then first differenced, it becomes:
$$ \begin{aligned} \Delta y_{t} & = \delta\ + \Delta\mathcal{z}{t} \ \Delta \mathcal{z} & = \phi\Delta\mathcal{z}{t-1}\ +\ \varepsilon_{t}\ -\ \varepsilon_{t-1} \ \end{aligned} .$$
The test statistic is
$$ t_{\phi=1}=\frac{\hat{\phi}-1}{SE(\hat{\phi})}$$
$\hat{\phi}$ is the least square estimate, and SE($\hat{\phi}$) is the usual standard error estimate. The test is a one-sided left tail test. If {$y_{t}$} is stationary, then it can be shown that
$$\sqrt{T}(\hat{\phi}-\phi)\xrightarrow[\text{}]{\text{d}}N(0,(1-\phi^{2}))$$
or
$$\hat{\phi}\overset{\text{A}}{\sim}N\bigg(\phi,\frac{1}{T}(1-\phi^{2}) \bigg)$$
and it follows that $t_{\phi=1}\overset{\text{A}}{\sim}N(0,1).$ However, under the null hypothesis of non-stationarity, the above result gives
$$ \hat{\phi}\overset{\text{A}}{\sim} N(0,1) $$
The following function will allow us to check for stationarity using the Augmented Dickey-Fuller (ADF) test.
def stationarity_test(X, cutoff=0.01):
# H_0 in adfuller is unit root exists (non-stationary)
# We must observe significant p-value to convince ourselves that the series is stationary
pvalue = adfuller(X)[1]
if pvalue < cutoff:
print('p-value = ' + str(pvalue) + ' The series ' + X.name +' is likely stationary.')
else:
print('p-value = ' + str(p
stationarity_test(A)
stationarity_test(B)
p-value = 4.0811223061569216e-17 The series A is likely stationary.
p-value = 0.7317208279589542 The series B is likely non-stationary.
Cointegration
The correlations between financial quantities are notoriously unstable. Nevertheless, correlations are regularly used in almost all multivariate financial problems. An alternative statistical measure to correlation is cointegration. This is probably a more robust measure of linkage between two financial quantities, but as yet there is little derivatives theory based on this concept.
Two stocks may be perfectly correlated over short timescales, yet diverge in the long run, with one growing and the other decaying. Conversely, two stocks may follow each other, never being more than a certain distance apart, but with any correlation, positive, negative, or varying. If we are delta hedging, then maybe the short timescale correlation matters, but not if we are holding stocks for a long time in an unhedged portfolio.
We’ve constructed an example of two cointegrated series. We’ll plot the difference between the two now so we can see how this looks.
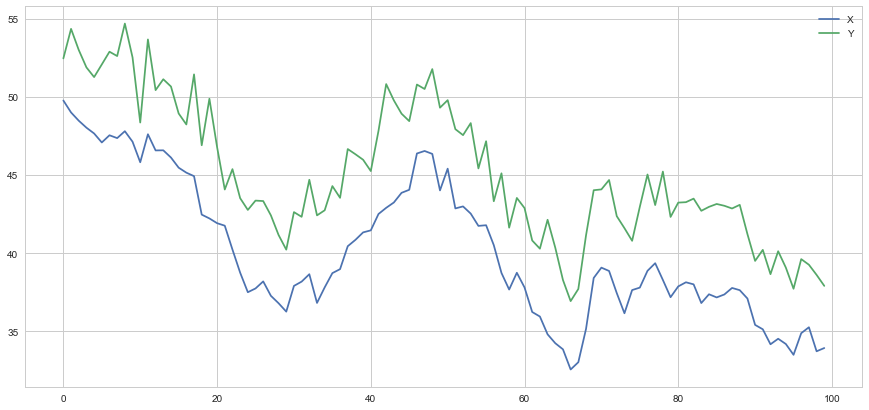
Testing for Cointegration
The steps in the cointegration test procdure:
- Test for a unit root in each component series $y_{t}$ individually, using the univariate unit root tests, says ADF, PP test.
- If the unit root cannot be rejected, then the next step is to test cointegration among the components, i.e., to test whether $\alpha Y_{t}$ is I(0).
If we find that the time series as a unit root, then we move on to the cointegration process. There are three main methods for testing for cointegration: Johansen, Engle-Granger, and Phillips-Ouliaris. We will primarily use the Engle-Granger test.
Let’s consider the regression model for $y_{t}$:
$$y_{1t} = \delta D_{t} + \phi_{1t}y_{2t} + \phi_{m-1} y_{mt} + \varepsilon_{t} $$
$D_{t}$ is the deterministic term. From there, we can test whether $\varepsilon_{t}$ is $I(1)$ or $I(0)$. The hypothesis test is as follows:
$$ \begin{aligned} H_{0} & : \varepsilon_{t} \sim I(1) \implies y_{t} \ (no \ cointegration) \ H_{1} & : \varepsilon_{t} \sim I(0) \implies y_{t} \ (cointegration) \ \end{aligned} $$
If the time series is cointegrated, then $y_{t}$ is cointegrated with a normalized cointegration vector $\alpha = (1, \phi_{1}, \ldots,\phi_{m-1}).$
We also use residuals $\varepsilon_{t}$ for unit root test.
$$ \begin{aligned} H_{0} & : \lambda = 0 \ (Unit \ Root) \ H_{1} & : \lambda < 1 \ (Stationary) \ \end{aligned} $$
This hypothesis test is for the model:
$$\Delta\varepsilon_{t}=\lambda\varepsilon_{t-1}+\sum^{p-1}{j=1}\varphi\Delta\varepsilon{t-j}+\alpha_{t}$$
The test statistic for the following equation:
$$t_{\lambda}=\frac{\hat{\lambda}}{s_{\hat{\lambda}}} $$
Now that you understand what it means for these time series to be cointegrated, we can test for it and measure it using python:
score, pvalue, _ = coint(X,Y)
print(pvalue)
Correlation vs. Cointegration
Correlation and cointegration, while theoretically similar, are anything but similar. To demonstrate this, we can look at examples of these time series that are correlated, but not cointegrated.
A simple example is two series that just diverge.
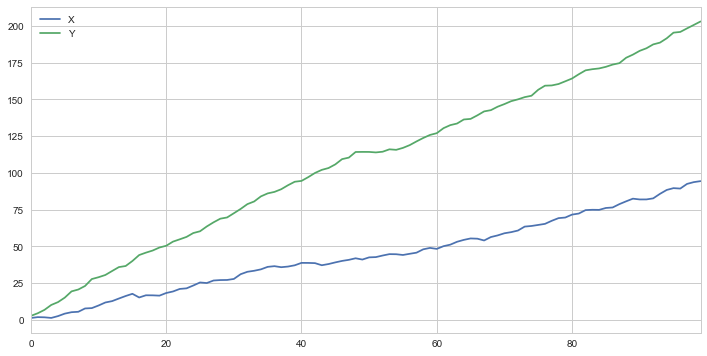
Next, we can print the correlation coefficient, $r$, and the cointegration test.
print('Correlation: ' + str(X_diverging.corr(Y_diverging)))
score, pvalue, _ = coint(X_diverging,Y_diverging)
print('Cointegration test p-value: ' + str(pvalue))
Correlation: 0.9918846224870514
Cointegration test p-value: 0.915621777573125
As we can see, there is a very strong (nearly perfect) correlation between series X and Y. However, our p-value for the cointegration test yields a result of 0.7092, which means there is no cointegration between time series X and Y.
Another example of this case is a normally distributed series and a sqaure wave.
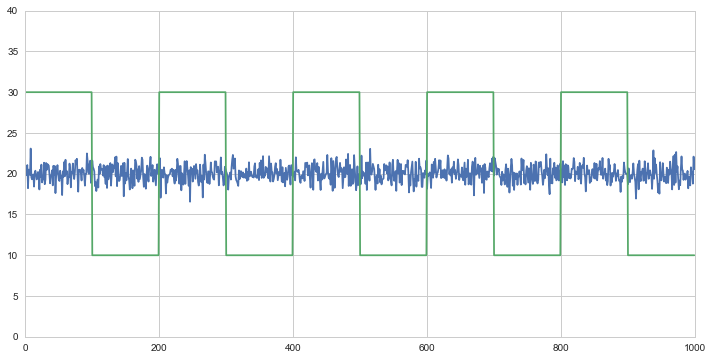
Although the correlation is incredibly low, the p-value shows that these time series are cointegrated.
Data Science in Trading
Before we begin, I’ll first define a function that makes it easy to find cointegrated security pairs using the concepts we’ve already covered.
def find_cointegrated_pairs(data):
n = data.shape[1]
score_matrix = np.zeros((n, n))
pvalue_matrix = np.ones((n, n))
keys = data.keys()
pairs = []
for i in range(n):
for j in range(i+1, n):
S1 = data[keys[i]]
S2 = data[keys[j]]
result = coint(S1, S2)
score = result[0]
pvalue = result[1]
score_matrix[i, j] = score
pvalue_matrix[i, j] = pvalue
if pvalue < 0.05:
pairs.append((keys[i], keys[j]))
return score_matrix, pvalue_matrix, pairs
We are looking through a set of tech companies to see if any of them are cointegrated. We’ll start by defining the list of securities we want to look through. Then we’ll get the pricing data for each security from the year 2013 - 2018.
As mentioned before, we have formulated an economic hypothesis that there is some sort of link between a subset of securities within the tech sector, and we want to test whether there are any cointegrated pairs. This incurs significantly less multiple comparisons bias than searching through hundreds of securities and slightly more than forming a hypothesis for an individual test.
We have decided to analyze the following technology stocks: AAPL, ADBE, SYMC, EBAY, MSFT, QCOM, HPQ, JNPR, AMD, and IBM.
We’ve also decided to include the S&P 500 in our analysis, just in case there was equity that was cointegrated with the entire market.
After extracting the historical prices, we will create a heatmap that will show the p-values of the cointegrated test between each pair of stocks. The heatmap will mask all pairs with a p-value greater than 0.05.

Our algorithm listed two pairs that are cointegrated: AAPL/EBAY, and ABDE/MSFT. We will analyze the ABDE/MSFT equity pair.
Calculating the Spread
Now we can plot the spread of these time series. To actually calculate the spread, we use a linear regression to get the coefficient for the linear combination to construct between our two securities, as mentioned with the Engle-Granger method before.
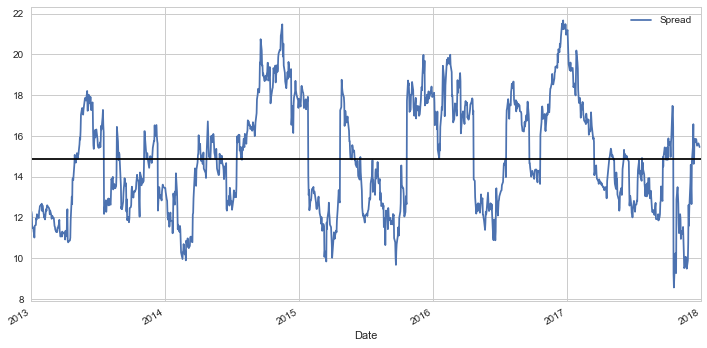
Alternatively, we can examine the ration between the time series.
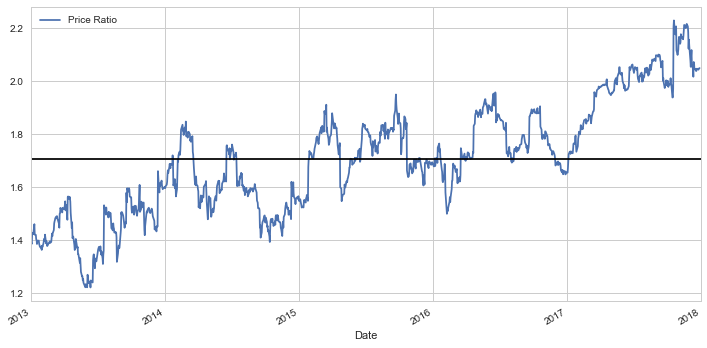
Regardless of whether or not we use the spread approach or the ratio approach, we can see that our first plot pair ADBE/SYMC tends to move around the mean. We now need to standardize this ratio because the absolute ratio might not be the most ideal way of analyzing this trend. For this, we need to use z-scores.
A z-score is the number of standard deviations a data point is from the mean. More importantly, the number of standard deviations above or below the population mean is from the raw score. The z-score is calculated by the following:
$$\mathcal{z}{i}=\frac{x{i}-\bar{x}}{s} $$
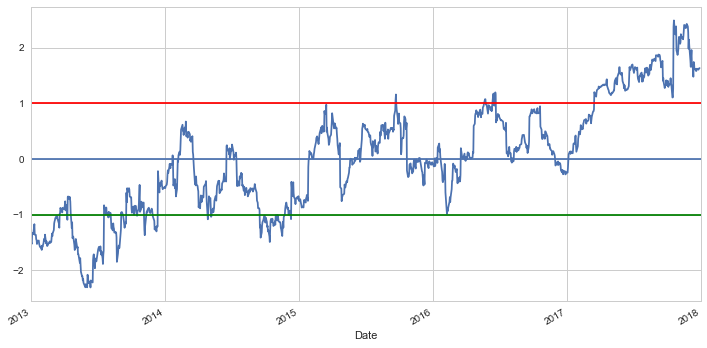
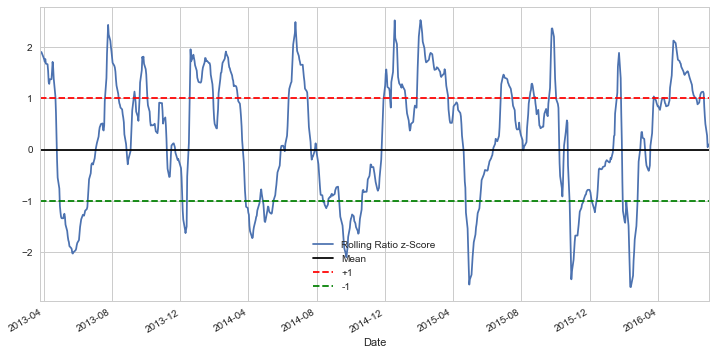
By setting two other lines placed at the z-score of 1 and -1, we can clearly see that for the most part, any big divergences from the mean eventually converge back. This is precisely what we want for a pairs trading strategy.
Trading Signals
When conducting any type of trading strategy, it’s always important to clearly define and delineate at what point you will actually make a trade. As in, what is the best indicator that I need to buy or sell a particular stock?
Setup rules
We’re going to use the ratio time series that we’ve created to see if it tells us whether to buy or sell a particular moment in time. We’ll start off by creating a prediction variable $Y$. If the ratio is positive, it will signal a “buy,” otherwise, it will signal a sell. The prediction model is as follows:
$$Y_{t} = sign(Ratio_{t+1}-Ratio_{t}) $$
What’s great about pair trading signals is that we don’t need to know absolutes about where the prices will go, all we need to know is where it’s heading: up or down.
Train Test Split
When training and testing a model, it’s common to have splits of 70/30 or 80/20. We only used a time series of 252 points (which is the number of trading days in a year). Before training and splitting the data, we will add more data points in each time series.
Feature Engineering
We need to find out what features are actually important in determining the direction of the ratio moves. Knowing that the ratios always eventually revert back to the mean, maybe the moving averages and metrics related to the mean will be important.
Let’s try using these features:
- 60 day Moving Average of Ratio
- 5 day Moving Average of Ratio
- 60 day Standard Deviation
- z score
Creating a Model
A standard normal distribution has a mean of 0 and a standard deviation 1. Looking at the plot, it’s pretty clear that if the time series moves 1 standard deviation beyond the mean, it tends to revert back towards the mean. Using these models, we can create the following trading signals:
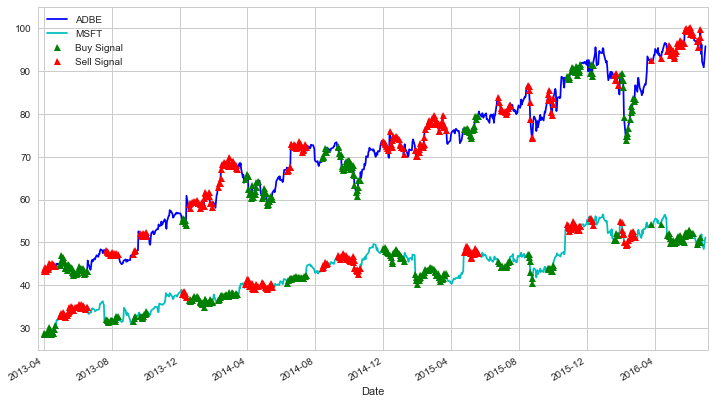
- Buy(1) whenever the z-score is below -1, meaning we expect the ratio to increase.
- Sell(-1) whenever the z-score is above 1, meaning we expect the ratio to decrease.
Training Optimizing
We can use our model on actual data
Areas of Improvement and Further Steps
This is by no means a perfect strategy and the implementation of our strategy isn’t the best. However, there are several things that can be improved upon.
1. Using more securities and more varied time ranges
For the pairs trading strategy cointegration test, I only used a handful of stocks. Naturally (and in practice) it would be more useful to use clusters within an industry. I only use the time range of only 5 years, which may not be representative of stock market volatility.
2. Dealing with overfitting
Anything related to data analysis and training models has much to do with the problem of overfitting. There are many different ways to deal with overfitting like validation, such as Kalman filters, and other statistical methods.
3. Adjusting the trading signals
Our trading algorithm fails to account for stock prices that overlap and cross each other. Considering that the code only calls for a buy or sell given its ratio, it doesn’t take into account which stock is actually higher or lower.
4. More advanced methods
This is just the tip of the iceberg of what you can do with algorithmic pairs trading. It’s simple because it only deals with moving averages and ratios. If you want to use more complicated statistics, feel free to do so. Other complex examples include subjects such as the Hurst exponent, half-life mean reversion, and Kalman Filters.
GitHub Code
Click here for the full Github Code and explainations.
Andre Sealy
Quant Research / Data Scientist / Writer
My research interests involves Quantitative Finance, Mathematics, Data Science and Machine Learning.